链表概述
链表是一种通过指针串联在一起的线性结构,每一个结点由两部分组成,一个是数据域一个是指针域(存放指向下一个结点的指针),最后一个结点的指针域指向 null(空指针的意思)。
链表的入口结点称为链表的头结点也就是 head。
上面讲的是我们最常见的单向链表,实际上链表还可以分为:
- 单向链表:一个结点指向下一个结点。
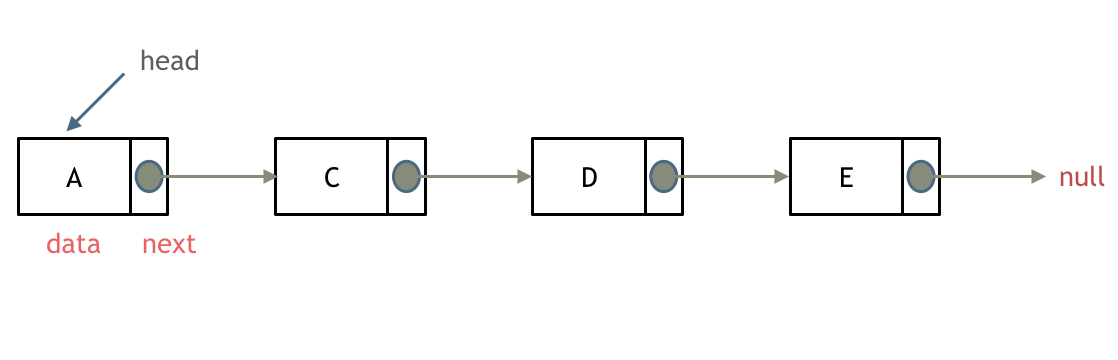
- 双向链表:每一个结点有两个指针域,一个指向下一个结点,一个指向上一个结点。
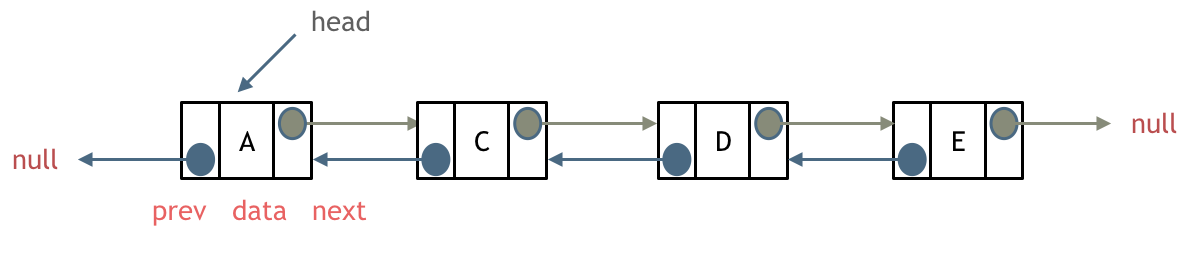
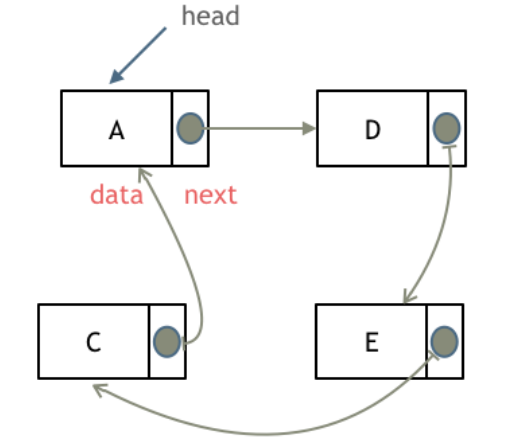
- 循环链表:能通过任何一个结点找到其他所有的结点,将两种 (双向/单向) 链表的最后一个结点指向第一个结点从而实现循环。
链表的存储方式
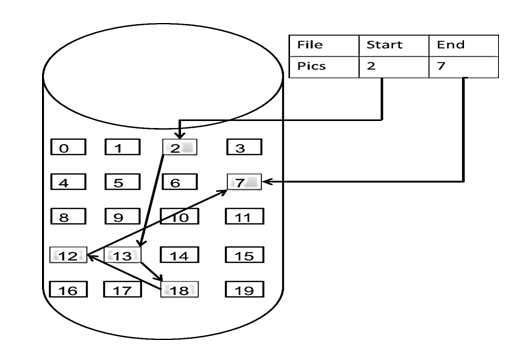
数组是在内存中是连续分布的,但是链表在内存中可不是连续分布的。
链表是通过指针域的指针链接在内存中各个结点。
所以链表中的结点在内存中不是连续分布的,而是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理。
如图:
链表的定义
单向链表的定义
java
public class ListNode {
// 结点的值
int val;
// 下一个结点
ListNode next;
// 节点的构造函数 (无参)
public ListNode() {
}
// 节点的构造函数 (有一个参数)
public ListNode(int val) {
this.val = val;
}
// 节点的构造函数 (有两个参数)
public ListNode(int val, ListNode next) {
this.val = val;
this.next = next;
}
}public class ListNode {
// 结点的值
int val;
// 下一个结点
ListNode next;
// 节点的构造函数 (无参)
public ListNode() {
}
// 节点的构造函数 (有一个参数)
public ListNode(int val) {
this.val = val;
}
// 节点的构造函数 (有两个参数)
public ListNode(int val, ListNode next) {
this.val = val;
this.next = next;
}
}链表的操作
下述的操作都默认为单向链表
添加结点
在链表中添加结点,需要先从头结点遍历至要插入位置的上一个结点,通过改变其指针至待添加的结点,以及将待添加的结点指向要插入位置原来的结点来实现,如图:
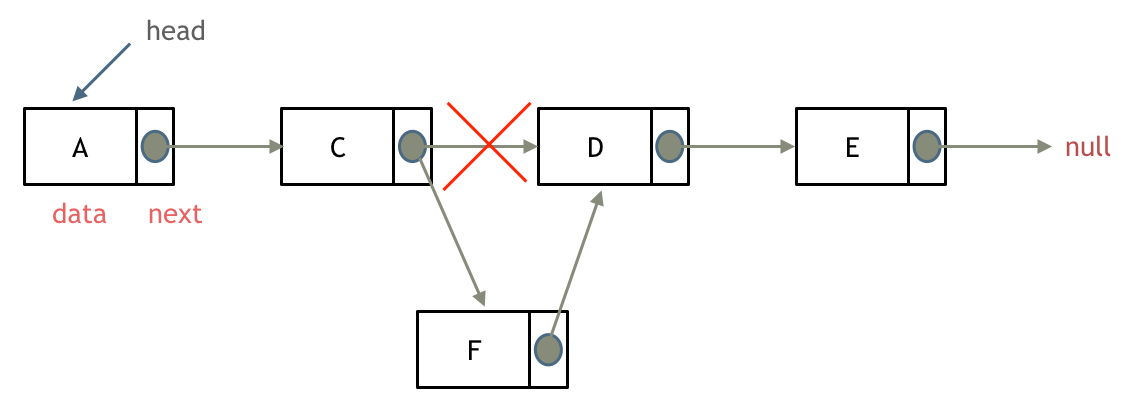
删除结点
在链表中删除结点,需要进行和添加结点正好相反的操作,但是都需要先遍历到要删除的结点的上一个结点(因为结点的引用在上一个结点),然后将上一个结点的指针,直接指向待删除结点再下一个结点,如图:
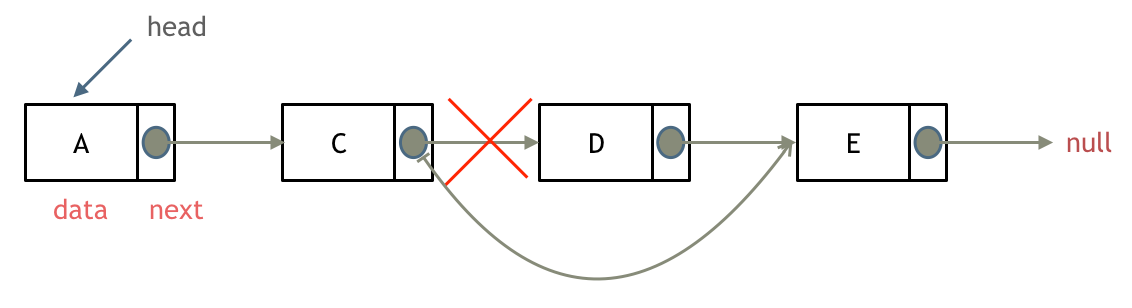
链表的性能
数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删,适合数据量不固定,频繁增删,较少查询的场景。
相关算法题
解链表相关算法题常用的技巧:
- 虚拟头结点
- 双指针/快慢指针
- 递归