原理篇 - volatile 关键字
几个基本概念
在介绍 volatile 之前,我们先回顾及介绍几个基本的概念。
内存可见性
在 Java 内存模型那一章我们介绍了 JMM 有一个主内存,每个线程有自己私有的工作内存,工作内存中保存了一些变量在主内存的拷贝。
内存可见性,指的是线程之间的可见性,当一个线程修改了共享变量时,另一个线程可以读取到这个修改后的值。
重排序
为优化程序性能,对原有的指令执行顺序进行优化重新排序。重排序可能发生在多个阶段,比如编译重排序、CPU 重排序等。
happens-before 规则
是一个给程序员使用的规则,只要程序员在写代码的时候遵循 happens-before 规则,JVM 就能保证指令在多线程之间的顺序性符合程序员的预期。
volatile 的内存语义
在 Java 中,volatile 关键字有特殊的内存语义。volatile 主要有以下两个功能:
- 保证变量的内存可见性
- 禁止 volatile 变量与普通变量重排序(JSR133 提出,Java 5 开始才有这个“增强的 volatile 内存语义”)
内存可见性
以一段示例代码开始:
public class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; // step 1
flag = true; // step 2
}
public void reader() {
if (flag) { // step 3
System.out.println(a); // step 4
}
}
}public class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; // step 1
flag = true; // step 2
}
public void reader() {
if (flag) { // step 3
System.out.println(a); // step 4
}
}
}在这段代码里,我们使用volatile关键字修饰了一个boolean类型的变量flag。
所谓内存可见性,指的是当一个线程对volatile修饰的变量进行写操作(比如 step 2)时,JMM 会立即把该线程对应的本地内存中的共享变量的值刷新到主内存;当一个线程对volatile修饰的变量进行读操作(比如 step 3)时,JMM 会把立即该线程对应的本地内存置为无效,从主内存中读取共享变量的值。
在这一点上,volatile 与锁具有相同的内存效果,volatile 变量的写和锁的释放具有相同的内存语义,volatile 变量的读和锁的获取具有相同的内存语义。
假设在时间线上,线程 A 先执行方法writer方法,线程 B 后执行reader方法。那必然会有下图:
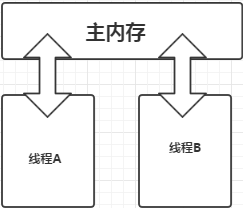
而如果flag变量没有用volatile修饰,在 step 2,线程 A 的本地内存里面的变量就不会立即更新到主内存,那随后线程 B 也同样不会去主内存拿最新的值,仍然使用线程 B 本地内存缓存的变量的值a = 0,flag = false。
禁止重排序
在 JSR-133 之前的旧的 Java 内存模型中,是允许 volatile 变量与普通变量重排序的。那上面的案例中,可能就会被重排序成下列时序来执行:
- 线程 A 写 volatile 变量,step 2,设置 flag 为 true;
- 线程 B 读同一个 volatile,step 3,读取到 flag 为 true;
- 线程 B 读普通变量,step 4,读取到 a = 0;
- 线程 A 修改普通变量,step 1,设置 a = 1;
可见,如果 volatile 变量与普通变量发生了重排序,虽然 volatile 变量能保证内存可见性,也可能导致普通变量读取错误。
所以在旧的内存模型中,volatile 的写 - 读就不能与锁的释放 - 获取具有相同的内存语义了。为了提供一种比锁更轻量级的线程间的通信机制,JSR-133专家组决定增强 volatile 的内存语义:严格限制编译器和处理器对 volatile 变量与普通变量的重排序。
编译器还好说,JVM 是怎么还能限制处理器的重排序的呢?它是通过内存屏障来实现的。
什么是内存屏障?硬件层面,内存屏障分两种:读屏障(Load Barrier)和写屏障(Store Barrier)。内存屏障有两个作用:
- 阻止屏障两侧的指令重排序;
- 强制把写缓冲区/高速缓存中的脏数据等写回主内存,或者让缓存中相应的数据失效。
注意这里的缓存主要指的是 CPU 缓存,如 L1,L2 等
编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。编译器选择了一个比较保守的 JMM 内存屏障插入策略,这样可以保证在任何处理器平台,任何程序中都能得到正确的 volatile 内存语义。这个策略是:
- 在每个 volatile 写操作前插入一个 StoreStore 屏障;
- 在每个 volatile 写操作后插入一个 StoreLoad 屏障;
- 在每个 volatile 读操作后插入一个 LoadLoad 屏障;
- 在每个 volatile 读操作后再插入一个 LoadStore 屏障。
大概示意图是这个样子:
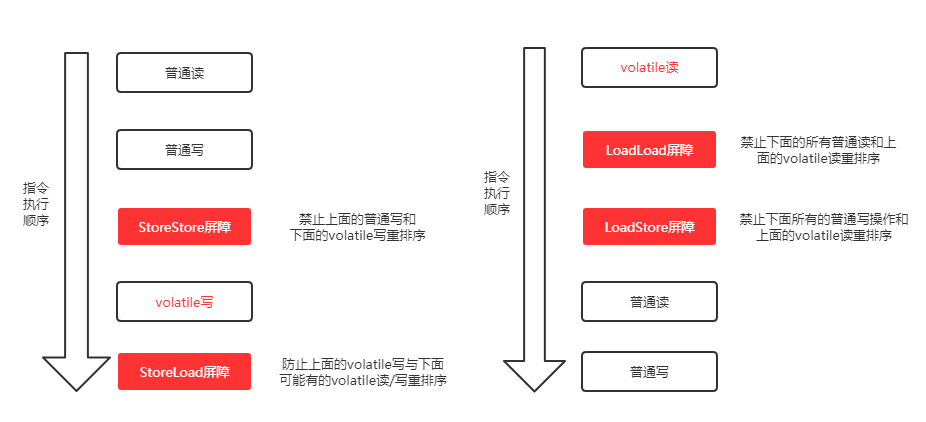
再逐个解释一下这几个屏障。注:下述 Load 代表读操作,Store 代表写操作
LoadLoad 屏障:对于这样的语句 Load1; LoadLoad; Load2,在 Load2 及后续读取操作要读取的数据被访问前,保证 Load1 要读取的数据被读取完毕。
StoreStore 屏障:对于这样的语句 Store1; StoreStore; Store2,在 Store2 及后续写入操作执行前,这个屏障会把 Store1 强制刷新到内存,保证 Store1 的写入操作对其它处理器可见。
LoadStore 屏障:对于这样的语句 Load1; LoadStore; Store2,在 Store2 及后续写入操作被刷出前,保证 Load1 要读取的数据被读取完毕。
StoreLoad 屏障:对于这样的语句 Store1; StoreLoad; Load2,在 Load2 及后续所有读取操作执行前,保证 Store1 的写入对所有处理器可见。它的开销是四种屏障中最大的(冲刷写缓冲器,清空无效化队列)。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能
对于连续多个 volatile 变量读或者连续多个 volatile 变量写,编译器做了一定的优化来提高性能,比如:
第一个 volatile 读;
LoadLoad 屏障;
第二个 volatile 读;
LoadStore 屏障
再介绍一下 volatile 与普通变量的重排序规则:
如果第一个操作是 volatile 读,那无论第二个操作是什么,都不能重排序;
如果第二个操作是 volatile 写,那无论第一个操作是什么,都不能重排序;
如果第一个操作是 volatile 写,第二个操作是 volatile 读,那不能重排序。
举个例子,我们在案例中 step 1,是普通变量的写,step 2 是 volatile 变量的写,那符合第 2 个规则,这两个 steps 不能重排序。而 step 3 是 volatile 变量读,step 4 是普通变量读,符合第 1 个规则,同样不能重排序。
但如果是下列情况:第一个操作是普通变量读,第二个操作是 volatile 变量读,那是可以重排序的:
// 声明变量
int a = 0; // 声明普通变量
volatile boolean flag = false; // 声明 volatile 变量
// 以下两个变量的读操作是可以重排序的
int i = a; // 普通变量读
boolean j = flag; // volatile 变量读// 声明变量
int a = 0; // 声明普通变量
volatile boolean flag = false; // 声明 volatile 变量
// 以下两个变量的读操作是可以重排序的
int i = a; // 普通变量读
boolean j = flag; // volatile 变量读volatile 的用途
从 volatile 的内存语义上来看,volatile 可以保证内存可见性且禁止重排序。
在保证内存可见性这一点上,volatile 有着与锁相同的内存语义,所以可以作为一个“轻量级”的锁来使用。但由于 volatile 仅仅保证对单个 volatile 变量的读/写具有原子性,而锁可以保证整个临界区代码的执行具有原子性。所以在功能上,锁比 volatile 更强大;在性能上,volatile 更有优势。
在禁止重排序这一点上,volatile 也是非常有用的。比如我们熟悉的单例模式,其中有一种实现方式是“双重锁检查”,比如这样的代码:
public class Singleton {
private static Singleton instance; // 不使用 volatile 关键字
// 双重锁检验
public static Singleton getInstance() {
if (instance == null) { // 第 7 行
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton(); // 第 10 行
}
}
}
return instance;
}
}public class Singleton {
private static Singleton instance; // 不使用 volatile 关键字
// 双重锁检验
public static Singleton getInstance() {
if (instance == null) { // 第 7 行
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton(); // 第 10 行
}
}
}
return instance;
}
}如果这里的变量声明不使用 volatile 关键字,是可能会发生错误的。它可能会被重排序:
instance = new Singleton(); // 第 10 行
// 可以分解为以下三个步骤
1 memory=allocate();// 分配内存 相当于 c 的 malloc
2 ctorInstanc(memory) //初始化对象
3 s=memory //设置 s 指向刚分配的地址
// 上述三个步骤可能会被重排序为 1-3-2,也就是:
1 memory=allocate();// 分配内存 相当于 c 的 malloc
3 s=memory //设置 s 指向刚分配的地址
2 ctorInstanc(memory) //初始化对象instance = new Singleton(); // 第 10 行
// 可以分解为以下三个步骤
1 memory=allocate();// 分配内存 相当于 c 的 malloc
2 ctorInstanc(memory) //初始化对象
3 s=memory //设置 s 指向刚分配的地址
// 上述三个步骤可能会被重排序为 1-3-2,也就是:
1 memory=allocate();// 分配内存 相当于 c 的 malloc
3 s=memory //设置 s 指向刚分配的地址
2 ctorInstanc(memory) //初始化对象而一旦假设发生了这样的重排序,比如线程 A 在第 10 行执行了步骤 1 和步骤 3,但是步骤 2 还没有执行完。这个时候另一个线程 B 执行到了第 7 行,它会判定 instance 不为空,然后直接返回了一个未初始化完成的 instance!
所以 JSR-133 对 volatile 做了增强后,volatile 的禁止重排序功能还是非常有用的。