ElasticSearch 核心概念
核心概念
- Near Realtime(NRT) 近实时。数据提交索引后,立马就可以搜索到。
- Cluster 集群,一个集群由一个唯一的名字标识,默认为“elasticsearch”。集群名称非常重要,具有相同集群名的节点才会组成一个集群。集群名称可以在配置文件中指定。
- Node 节点:存储集群的数据,参与集群的索引和搜索功能。像集群有名字,节点也有自己的名称,默认在启动时会以一个随机的 UUID 的前七个字符作为节点的名字,你可以为其指定任意的名字。通过集群名在网络中发现同伴组成集群。一个节点也可是集群。
- Index 索引: 一个索引是一个文档的集合(等同于 solr 中的集合)。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引。
- Type 类型:指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从 6.0.0 版本起已废弃,一个索引中只存放一类数据。
- Document 文档:被索引的一条数据,索引的基本信息单元,以 JSON 格式来表示。
- Shard 分片:在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上。
- Replication 备份: 一个分片可以有多个备份(副本)
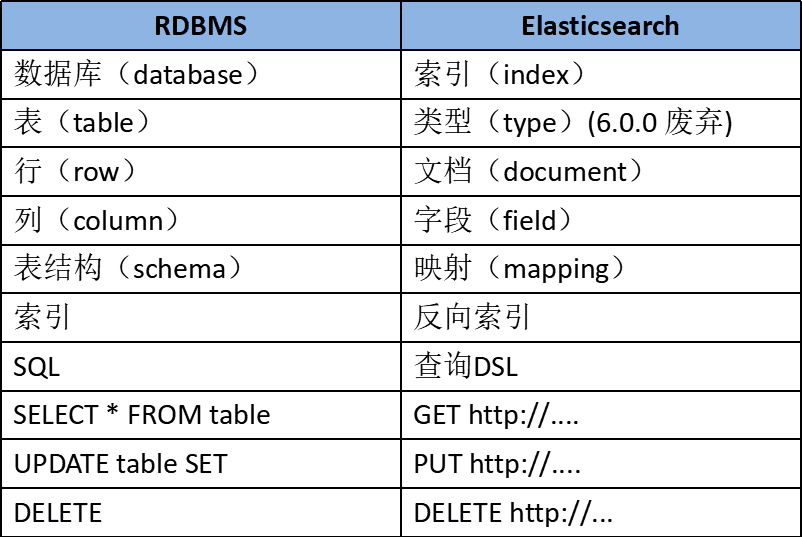
为了方便理解,作一个 ES 和数据库的对比:
倒排索引
什么是倒排索引:
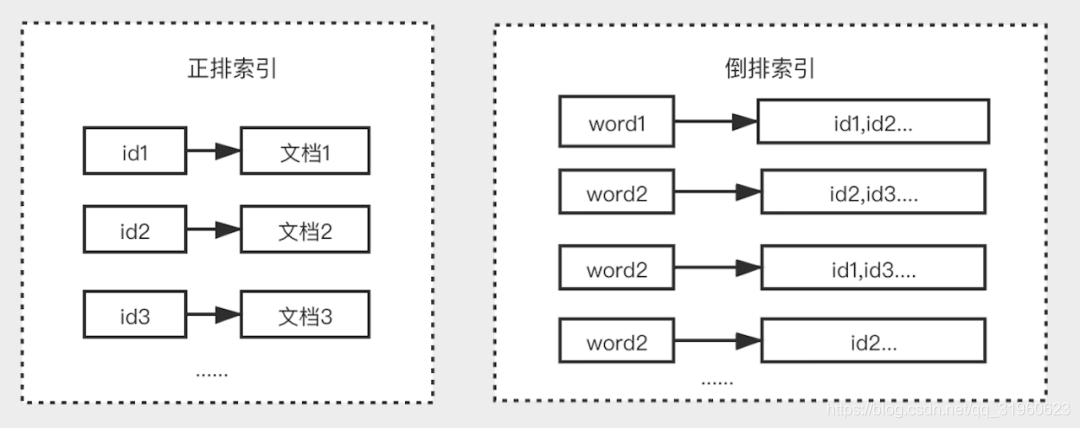
倒排索引也叫反向索引,通俗来讲正向索引是通过 key 找 value,反向索引则是通过 value 找 key。
正排索引与倒排索引比较:
- 正排索引:是以文档对象的唯一 ID 作为索引,以文档内容作为记录的结构。
- 倒排索引:Inverted index,指的是将文档内容中的单词作为索引,将包含该词的文档 ID 作为记录的结构。
Elasticsearch 分别为每个 field 都建立了一个倒排索引,这些 field 都值称为 term,值对应的 id 列表就是 Posting List 倒排列表。
倒排列表记录了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项 (Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
为了提高查询效率,又增加了 Term Dictionary 和 Term Index 的概念。
- Term Dictionary:
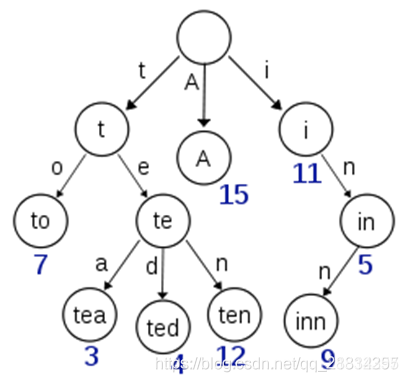
Elasticsearch 为了能快速找到某个 term,将所有的 term 排个序,二分法查找 term,logN 的查找效率,就像通过字典查找一样,这就是 Term Dictionary。现在再看起来,似乎和传统数据库通过 B-Tree 的方式类似,为什么说比 B-Tree 的查询快呢?
- Term Index:
B-Tree 通过减少磁盘寻道次数来提高查询性能,Elasticsearch 也是采用同样的思路,直接通过内存查找 term,不读磁盘,但是如果 term 太多,term dictionary 也会很大,放内存不现实,于是有了 Term Index,就像字典里的索引页一样,A 开头的有哪些 term,分别在哪页,可以理解 term index 是一颗树
这棵树不会包含所有的 term,它包含的是 term 的一些前缀。通过 term index 可以快速地定位到 term dictionary 的某个 offset,然后从这个位置再往后顺序查找
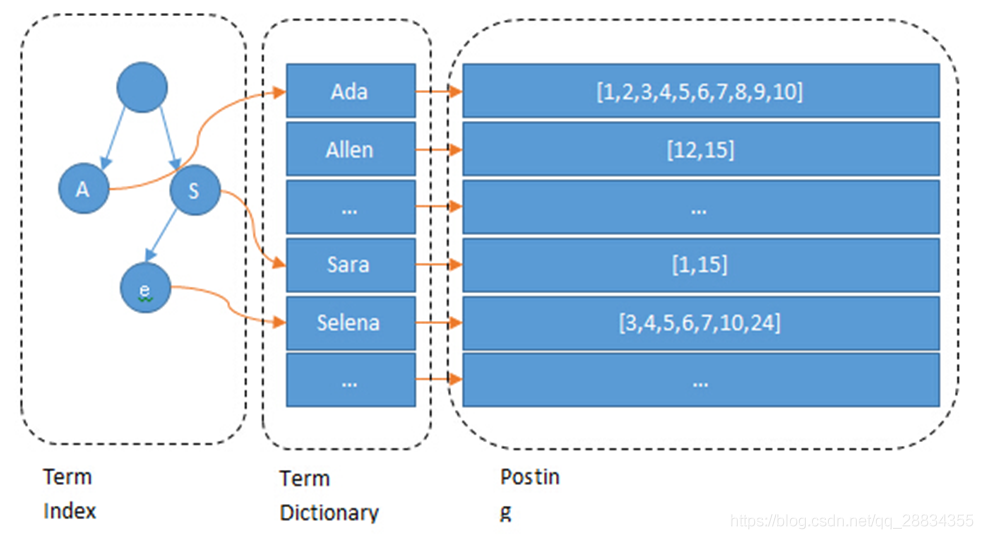
所以 term index 不需要存下所有的 term,而仅仅是他们的一些前缀与 Term Dictionary 的 block 之间的映射关系,再结合 FST(Finite State Transducers) 的压缩技术,可以使 term index 缓存到内存中。从 term index 查到对应的 term dictionary 的 block 位置之后,再去磁盘上找 term,大大减少了磁盘随机读的次数。
数据类型
Elaticsearch 支持的数据类型可以参见 Field data types | Elasticsearch Guide | Elastic
下面介绍几类常用的数据类型:字符串类型、数字类型、boolean 和 binary 类型、日期类型、范围类型。
字符串类型
text 类型:当一个字段需要用于全文搜索 (会被分词),比如产品名称、产品描述信息,就应该使用 text 类型。该类型字段会通过分析器转成 terms list,然后存入索引。该类型字段不用于排序、聚合操作。
keyword 类型:当一个字段需要按照精确值进行过滤、排序、聚合等操作时,就应该使用 keyword 类型。该类型的字段值不会被分析器处理(分词)
数字类型
byte有符号的 8 位整数,范围:[-128 ~ 127]short有符号的 16 位整数,范围:[-32768 ~ 32767]integer有符号的 32 位整数,范围:[−231−231 ~ 231231-1]long有符号的 64 位整数,范围:[−263−263 ~ 263263-1]float32 位单精度浮点数double64 位双精度浮点数half_float16 位半精度 IEEE 754 浮点类型scaled_float缩放类型的的浮点数,比如 price 字段只需精确到分,57.34 缩放因子为 100, 存储结果为 5734
boolean、binary 类型
boolean 类型:可以使用 boolean 类型的(true、false)也可以使用 string 类型的(“true”、“false”):
binary 类型:二进制类型是 Base64 编码字符串的二进制值,不以默认的方式存储,且不能被搜索。
日期类型
官方文档:Date field type
JSON 没有日期数据类型,所以在 Elasticsearch 中,日期可以是:
- 包含格式化日期的字符串,"2018-10-01", 或"2018/10/01 12:10:30"。
- 代表时间毫秒数的长整型数字。
- 代表时间秒数的整数。
可以不指定日期格式,也可以指定多个日期格式:
- 使用 format 指定格式:若未指定格式,则使用默认格式:
strict_date_optional_time||epoch_millis
{
"mappings": {
"my_type": {
"properties": {
"date": {
"type": "date"
}
}
}
}
}{
"mappings": {
"my_type": {
"properties": {
"date": {
"type": "date"
}
}
}
}
}- 指定多个 format:使用双竖线||分隔指定多种日期格式,每个格式都会被依次尝试,直到找到匹配的。
{
"mappings": {
"my_type": {
"properties": {
"date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}{
"mappings": {
"my_type": {
"properties": {
"date": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}范围类型
官方文档:Range field types
integer_range-2^31^ ~ 2^31^−1long_range−2^63^ ~ 2^63^−1float_range32 位单精度浮点型double_range64 位双精度浮点型date_range64 位整数,毫秒计时ip_rangeIP 值的范围,支持 IPV4 和 IPV6, 或者这两种同时存在
索引操作
Index API
一个索引就是一个拥有几分相似特征的文档的集合。比如说订单数据的索引,商品数据的索引。
一个索引由一个名字来标识(必须全部是小写字母)。并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
索引的创建方式:
- 在插入 doc 时根据 doc 结构动态映射并创建索引
PUT data/_doc/1
{ "count": 5 }PUT data/_doc/1
{ "count": 5 }- 手动指定
settings和mappings,显示映射创建索引
PUT /my-index-000001
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}PUT /my-index-000001
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}索引常用的 RestApi:
- 创建索引
PUT /{index}
{
"settings": { ... any settings ... },
"mappings": {
"properties": { ... any properties ... }
}
}PUT /{index}
{
"settings": { ... any settings ... },
"mappings": {
"properties": { ... any properties ... }
}
}- 查询索引
# 查询索引全部信息
GET /{index}
# 查询索引的映射信息
GET /{index}/_mapping
# 查询索引的设置信息
GET /{index}/_settings
# 查询特定字段的映射信息
GET /{index}/_mapping/field/{fieldName}# 查询索引全部信息
GET /{index}
# 查询索引的映射信息
GET /{index}/_mapping
# 查询索引的设置信息
GET /{index}/_settings
# 查询特定字段的映射信息
GET /{index}/_mapping/field/{fieldName}- 添加字段
PUT /{index}/_mapping
{
"properties": { ... any properties ... }
}PUT /{index}/_mapping
{
"properties": { ... any properties ... }
}mappings 属性
在 properties 里面,每个属性除了它基本的 type 参数外,还有一些其他参数,完整的列表参见 Mapping Params
这里介绍几个常用的参数:analyzer 和 fields
analyzer
analyzer 参数定义 text 字段索引和查询所使用的分析器,默认使用 es 自带的 Standard 标准分析器。
查询分析时,除非使用 search_analyzer 映射参数覆盖,否则也是使用的也是 analyzer 定义的分析器。
- analyzer:用于索引的分析器,包括停用词设置。
- search_analyzer:用于非短语查询的分析器,该设置将删除停用词。
- search_quote_analyzer:短语查询的分析器,不会删除停用词。
analyzer 有几个约束:
- 只有类型为
text的属性支持该参数; - 不可以在更新 mapping 的时候使用;
- 使用之前最好先进行测试,确保可以正确分词
示例,使用 ik 分词器:
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}