Kafka 消息队列
Kafka 简介
Kafka 是一个分布式、分区的、多副本的、多订阅者,基于 zookeeper 协调的分布式日志系统,可作为消息中间件。
应用场景
- 缓存/消峰:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
- 解耦:允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
- 异步通信:允许把一个消息放入队列,但不立即处理它,然后在需要的时候再去处理它。
优缺点
Kafka 是一个分布式流处理平台,具有以下优点:
- 高吞吐量和可伸缩性:Kafka 可以处理每秒数百万条消息,并且可以通过添加更多的节点轻松扩展。
- 高容错性:Kafka 使用分布式复制机制来保证数据的可靠性和持久性,即使其中一些节点失败也不会造成数据丢失。
- 高性能:Kafka 采用了顺序读写磁盘的方式进行消息存储,具有较低的延迟和高吞吐量。
- 支持多种消费者:Kafka 的消费者模型支持同时有多个消费者组订阅同一个主题,并且可以准确地跟踪每个消费者在主题中的消费进度。
尽管 Kafka 具有许多优点,但它也有一些缺点:
- 复杂性:配置和管理 Kafka 集群可能需要一定的技术知识和经验。对于新手来说,上手可能会有一定的学习曲线。
- 存储需求较高:由于 Kafka 默认将所有消息持久化到磁盘上,所以需要相应的存储空间。如果消息量很大,存储需求可能会变得很高。
- 无法直接修改数据:一旦消息被写入 Kafka,就无法直接修改它们。如果需要更改消息内容,只能通过写入新的消息来实现。
- API 稳定性变化:Kafka 的 API 在不同版本之间可能会发生一些变化,这可能导致升级和兼容性方面的挑战。
综上所述,Kafka 是一种高性能、可伸缩、可靠的分布式流处理平台,但在配置和管理上有一定的复杂性,并且需要额外的存储空间。
Kafka 基础架构
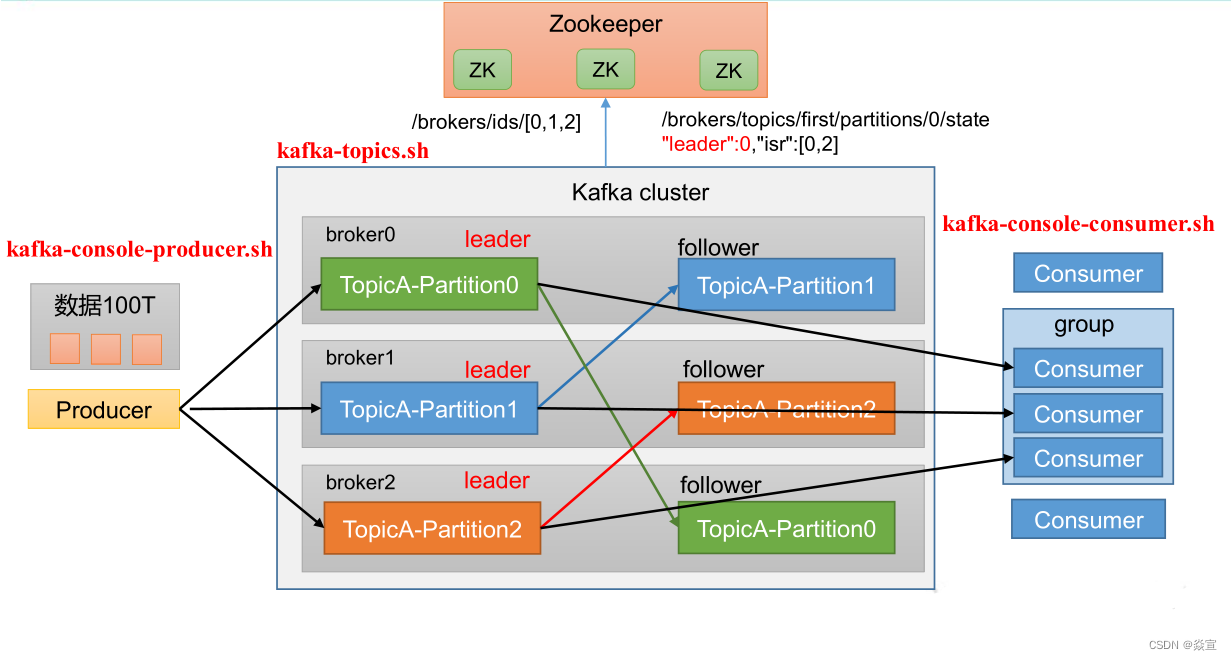
Producer:生产者,发送消息的一方。生产者负责创建消息,然后将其发送到 Kafka。Consumer:消费者,接受消息的一方。消费者连接到 Kafka 上并接收消息,进而进行相应的业务逻辑处理。Consumer Group:一个消费者组可以包含一个或多个消费者。使用多分区 + 多消费者方式可以极大提高数据下游的处理速度,同一消费组中的消费者不会重复消费消息,同样的,不同消费组中的消费者消息消息时互不影响。Kafka 就是通过消费组的方式来实现消息 P2P 模式和广播模式。Broker:服务代理节点。一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。Topic:Kafka 中的消息以 Topic 为单位进行划分,生产者将消息发送到特定的 Topic,而消费者负责订阅 Topic 的消息并进行消费。Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,个 一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
kafka 通过分区策略,将不同的分区分配在一个集群中的 broker 上,一般会分散在不同的 broker 上,当只有一个 broker 时,所有的分区就只分配到该 Broker 上。
消息会通过负载均衡发布到不同的分区上,消费者会监测偏移量来获取哪个分区有新数据,从而从该分区上拉取消息数据。分区数越多,在一定程度上会提升消息处理的吞吐量;
Offset:offset 是消息在分区中的唯一标识,Kafka 通过它来保证消息在分区内的顺序性,不过 offset 并不跨越分区,也就是说,Kafka 保证的是分区有序性而不是主题有序性。Replication:副本,是 Kafka 保证数据高可用的方式,Kafka 同一 Partition 的数据可以在多 Broker 上存在多个副本,通常只有主副本对外提供读写服务,当主副本所在 broker 崩溃或发生网络异常,Kafka 会在 Controller 的管理下会重新选择新的 Leader 副对外提供读写服务。Record:实际写入 Kafka 中并可以被读取的消息记录。每个 record 包含了 key、value 和 timestamp。
消费组、消费者和分区、主题的关系:
- 一个
consumer group可能有若干个consumer实例; - 对于同一个
group而言,topic的每条消息只能被发送到group下的一个consumer实例上; topic消息可以被发送到多个consumer group中;
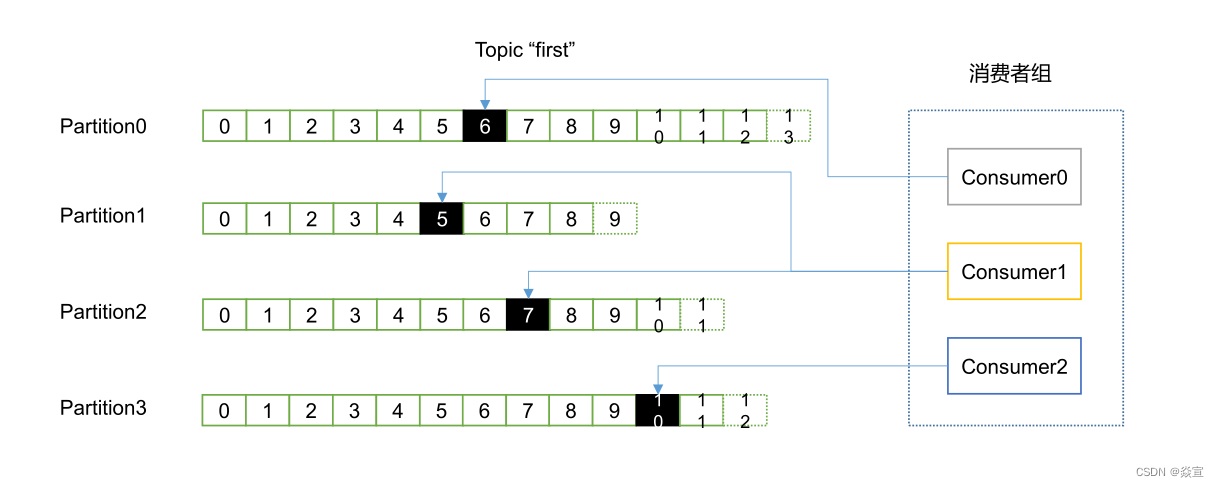
生产者
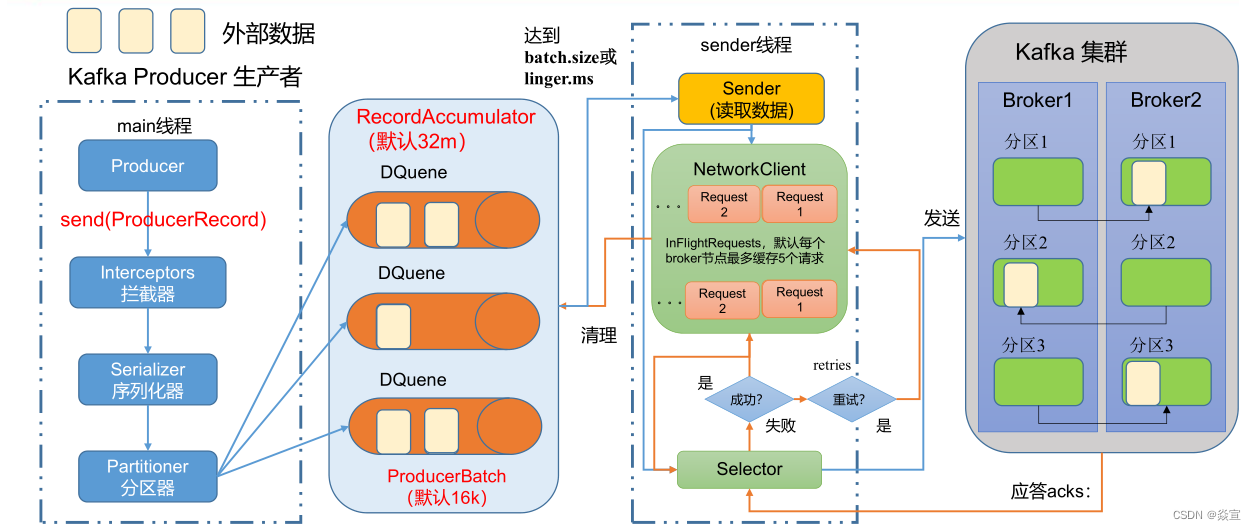
在消息发送的过程中,涉及到了两个线程:main 线程和 Sender 线程。在 main 线程中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
- producer 先从 zookeeper 的 "/brokers/…/state"节点找到该 partition 的 leader
- producer 将消息发送给该 leader
- leader 将消息写入本地 log
- followers 从 leader pull 消息,写入本地 log 后向 leader 发送 ACK
- leader 收到所有 ISR 中的 replication 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset)并向 producer 发送 ACK
相关参数:
• batch.size:只有数据积累到 batch.size 之后,sender 才会发送数据。默认 16k;
• linger.ms:如果数据迟迟未达到 batch.size,sender 等待 linger.time 之后就会发送数据。单位 ms,默认值是 0ms,表示没有延迟。
acks 应答级别 重要
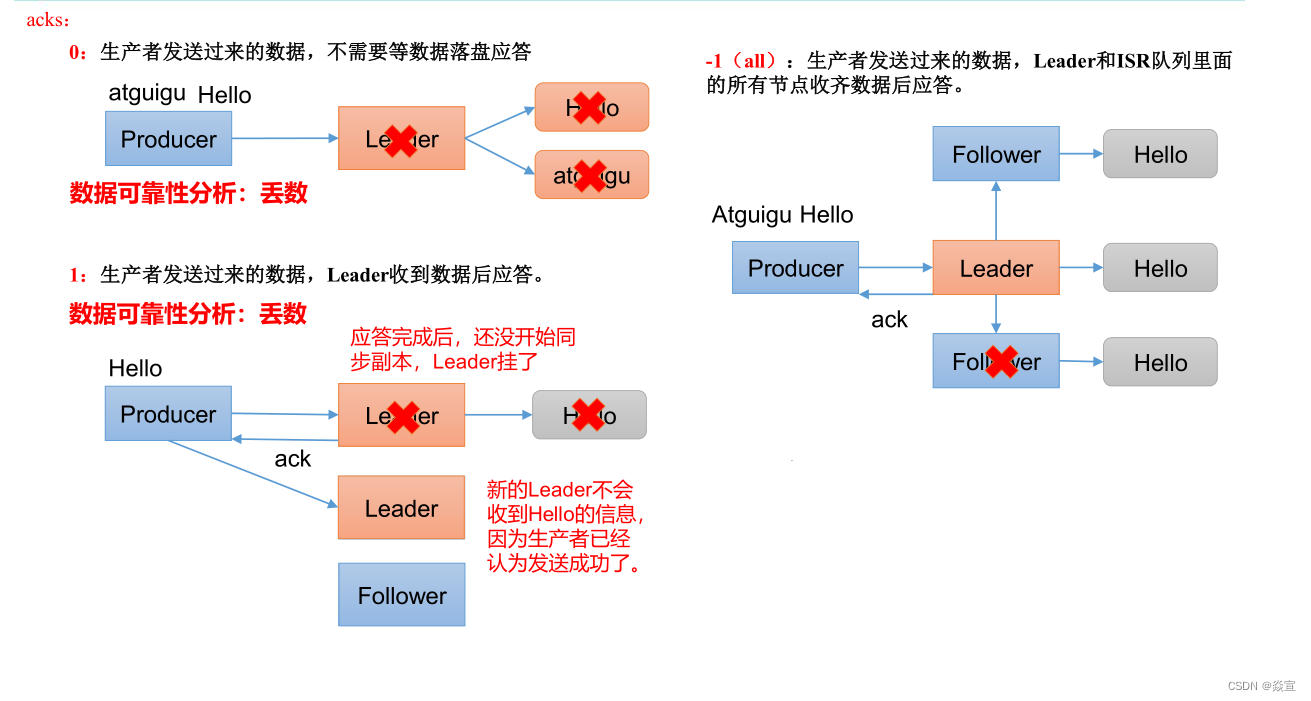
- acks=0,生产者发送过来数据就不管了,可靠性差,效率高;
- acks=1,生产者发送过来数据 Leader 应答,可靠性中等,效率中等;
- acks=-1,生产者发送过来数据 Leader 和 ISR 队列里面所有 Follwer 应答,可靠性高,效率低。
acks 设置:
在生产环境中,acks=0 很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据,对可靠性要求比较高的场景。
数据完全可靠条件:ACK 级别设置为 -1 + 分区副本大于等于 2 + ISR 里应答的的最小副本数量大于等于 2
消费者
队列和发布订阅两种模型
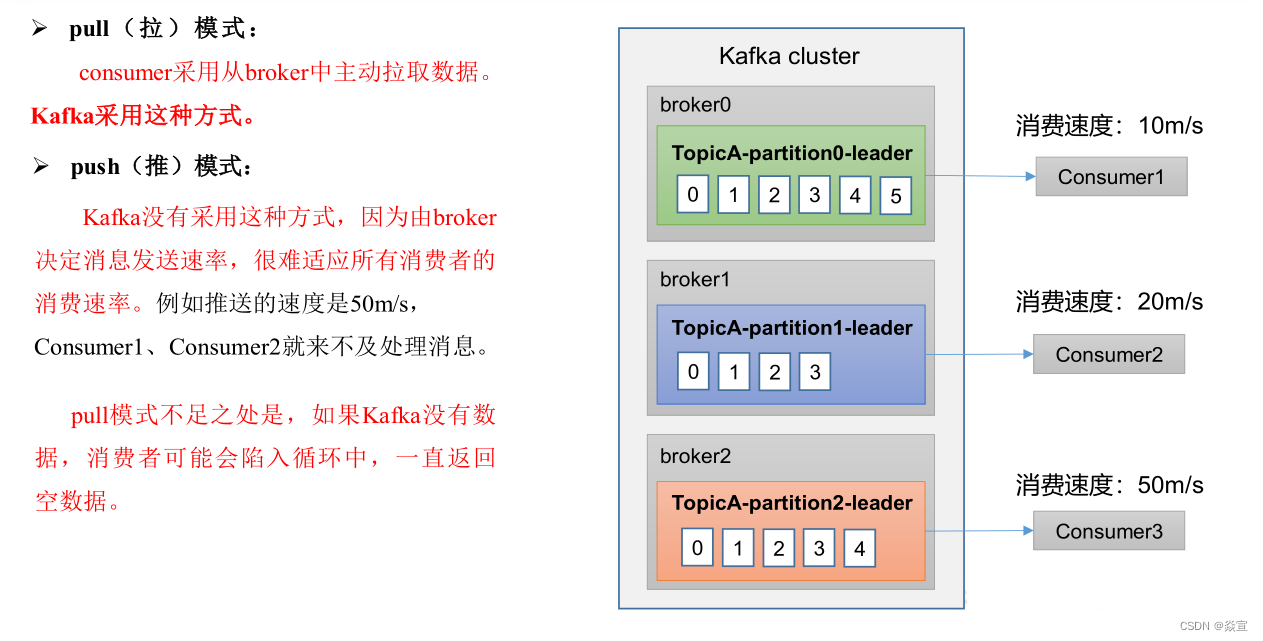
Kafka 同时支持基于队列和基于发布/订阅的两种消息引擎模型,事实上 Kafka 是通过 consumer group 实现对这两种模型的支持:
- 所有 consumer 实例都属于相同 group—实现基于队列的模型,每条消息只会被一个 consumer 实例处理
- consumer 实例都属于不同 group—实现基于发布/订阅的模型,极端的情况是每个 consumer 实例都设置完全不同都 group,这样 kafka 消息就会被广播到所有 consumre 实例
消费者初始化流程
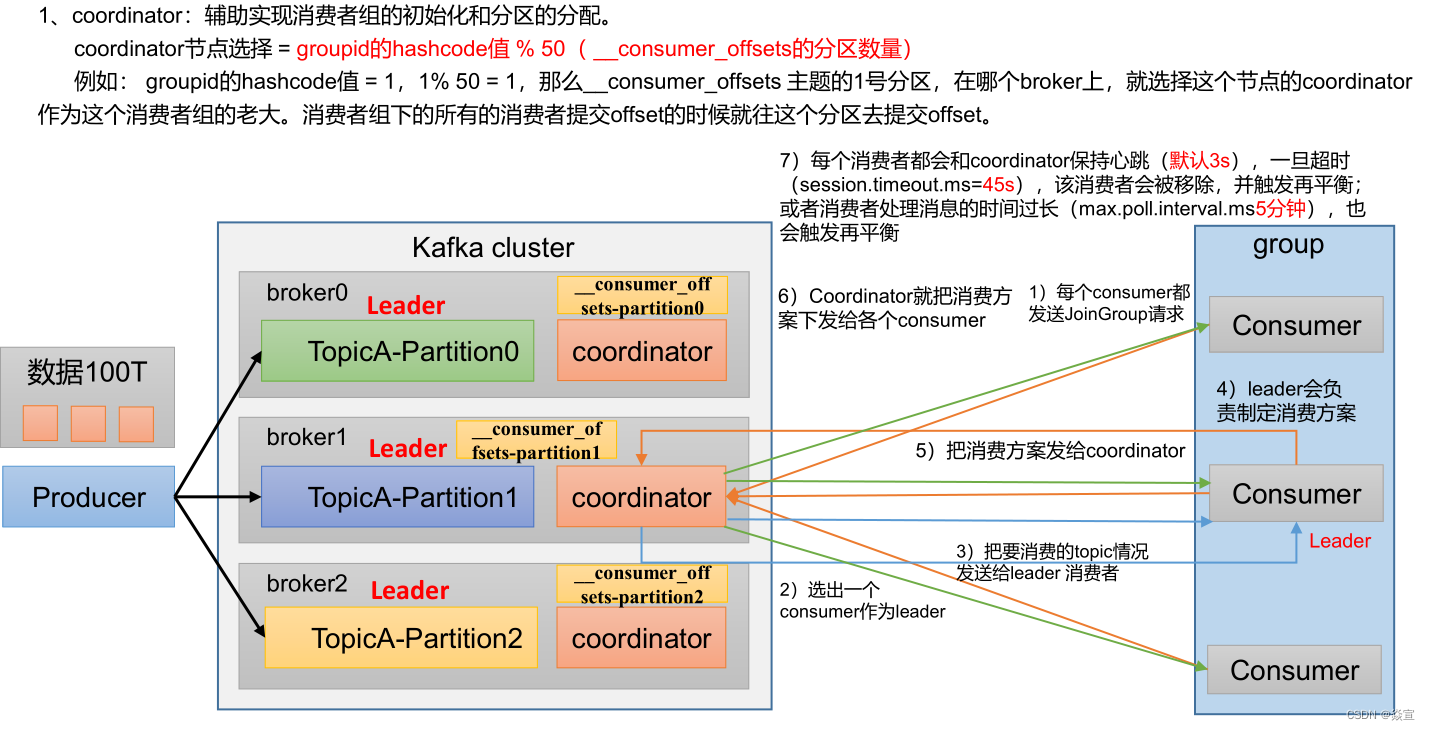
一旦 consumer 订阅了 topic,所有消费逻辑包括 coordinator 的协调、消费者组的 rebalance 以及数据的获取都会在主逻辑 poll 方法的一次调用中被执行,这样用户很容易使用一个线程来管理 consumer I/O 操作。
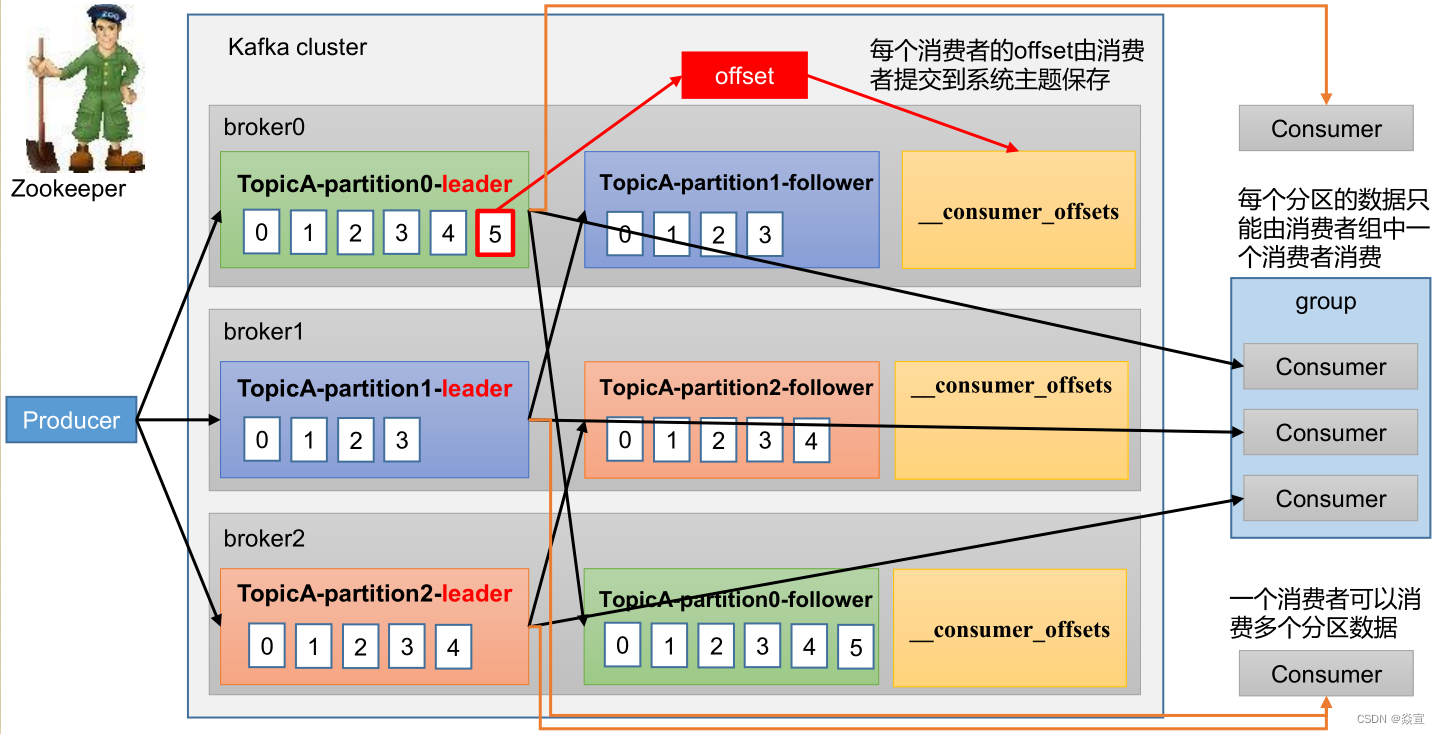
消费者工作流程
漏消费和重复消费
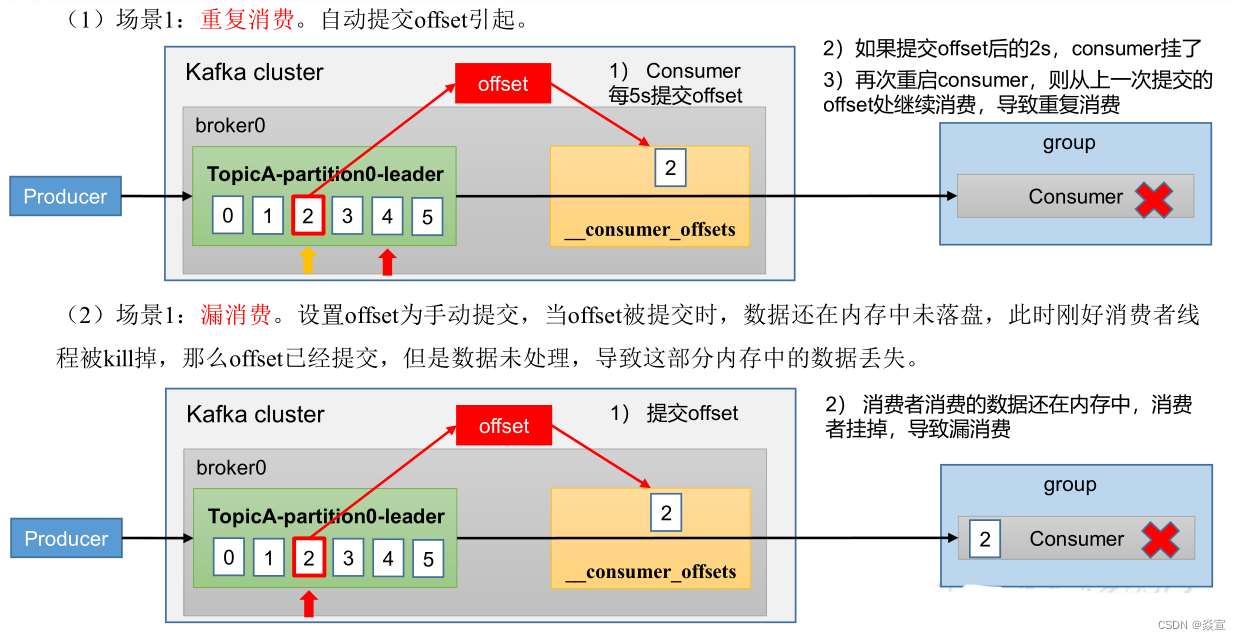
重复消费涉及到的相关参数:
enable.auto.commit:表示消费者会周期性自动提交消费的 offset。默认值 true。auto.commit.interval.ms:在 enable.auto.commit 为 true 的情况下,自动提交的间隔。默认值 5 秒。max.poll.records:单次消费者拉取的最大数据条数,默认值 500。max.poll.interval.ms:表示若在阈值时间之内消费者没有消费完上一次 poll 的消息,consumer client 会主动向 coordinator 发起 LeaveGroup 请求,触发 Rebalance;然后 consumer 重新发送 JoinGroup 请求。session.timeout.ms: Coordinator 检测 consumer 发生崩溃所需的时间。在这个时间内如果 Coordinator 未收到 Consumer 的任何消息,那 Coordinator 就认为 Consumer 挂了。默认值 10 秒。heartbeat.interval.ms:标识 Consumer 给 Coordinator 发一个心跳包的时间间隔。heartbeat.interval.ms 越小,发的心跳包越多。默认值 3 秒。
重复消费的解决方法:
提高消费者的处理速度
例如:对消息处理中比较耗时的步骤可通过异步的方式进行处理、利用多线程处理等。在缩短单条消息消费的同时,根据实际场景可将 max.poll.interval.ms 值设置大一点,避免不必要的 Rebalance。可根据实际消息速率适当调小 max.poll.records 的值。
引入消息去重机制
例如:生成消息时,在消息中加入唯一标识符如消息 id 等。在消费端,可以保存最近的 max.poll.records 条消息 id 到 redis 或 mysql 表中,这样在消费消息时先通过查询去重后,再进行消息的处理。
Kafka 部署
参考 Kafka 部署
SpringBoot 使用 Kakfa
依赖配置
- 引入依赖(版本自定)
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency><dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>- application 配置(示例)
配置文件类:org.springframework.boot.autoconfigure.kafka.KafkaProperties
生产者配置:
spring:
kafka:
bootstrap-servers: ${KAFKA_HOST:zeus-kafka}:${KAFKA_PORT:9092}
producer:
batch-size: 16384 # 默认 single request 批处理大小(以字节为单位),默认 16KB = 16384
acks: -1 # 应答级别:多少个分区副本备份完成时向生产者发送 ack 确认 (可选 0、1、all/-1)
retries: 10 # 消息发送重试次数
buffer-memory: 33554432 # 缓存容量。默认值 32MB = 33554432
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
properties:
linger:
ms: 2000 #提交延迟spring:
kafka:
bootstrap-servers: ${KAFKA_HOST:zeus-kafka}:${KAFKA_PORT:9092}
producer:
batch-size: 16384 # 默认 single request 批处理大小(以字节为单位),默认 16KB = 16384
acks: -1 # 应答级别:多少个分区副本备份完成时向生产者发送 ack 确认 (可选 0、1、all/-1)
retries: 10 # 消息发送重试次数
buffer-memory: 33554432 # 缓存容量。默认值 32MB = 33554432
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
properties:
linger:
ms: 2000 #提交延迟消费者配置:
spring:
kafka:
# kafka 服务地址,可以有多个用,隔开
bootstrap-servers: ${KAFKA_HOST:zeus-kafka}:${KAFKA_PORT:9092}
consumer:
group-id: zeus-test-consumer # 默认的消费组 ID
enable-auto-commit: true # 是否自动提交 offset
auto-commit-interval: 2000 # 提交 offset 延时,单位 ms
heartbeat-interval: 10000 # ⼼跳与消费者协调员之间的预期时间(以毫秒为单位)
# 当 kafka 中没有初始 offset 或 offset 超出范围时将自动重置 offset
# - earliest:重置为分区中最小的 offset;
# - latest:重置为分区中最新的 offset(消费分区中新产生的数据);
# - none:只要有一个分区不存在已提交的 offset,就抛出异常;
auto-offset-reset: latest
max-poll-records: 500 # 单次拉取消息的最大条数
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
properties:
session:
timeout:
ms: 120000 # 消费会话超时时间(超过这个时间 consumer 没有发送心跳,就会触发 rebalance 操作)
request:
timeout:
ms: 18000 # 消费请求的超时时间
listener:
ack-mode: manual_immediate # manual_immediate-手动 ack 后立即提交;batch-批量自动确认;RECORD-单条自动确认;
type: batch # 批量消费spring:
kafka:
# kafka 服务地址,可以有多个用,隔开
bootstrap-servers: ${KAFKA_HOST:zeus-kafka}:${KAFKA_PORT:9092}
consumer:
group-id: zeus-test-consumer # 默认的消费组 ID
enable-auto-commit: true # 是否自动提交 offset
auto-commit-interval: 2000 # 提交 offset 延时,单位 ms
heartbeat-interval: 10000 # ⼼跳与消费者协调员之间的预期时间(以毫秒为单位)
# 当 kafka 中没有初始 offset 或 offset 超出范围时将自动重置 offset
# - earliest:重置为分区中最小的 offset;
# - latest:重置为分区中最新的 offset(消费分区中新产生的数据);
# - none:只要有一个分区不存在已提交的 offset,就抛出异常;
auto-offset-reset: latest
max-poll-records: 500 # 单次拉取消息的最大条数
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
properties:
session:
timeout:
ms: 120000 # 消费会话超时时间(超过这个时间 consumer 没有发送心跳,就会触发 rebalance 操作)
request:
timeout:
ms: 18000 # 消费请求的超时时间
listener:
ack-mode: manual_immediate # manual_immediate-手动 ack 后立即提交;batch-批量自动确认;RECORD-单条自动确认;
type: batch # 批量消费TIP
- batch-size 和 linger.ms 这两个条件都设置时,只要满足其中一个条件,就会发送消息。
主题配置:
可通过注入 NewTopic 示例,在启动时创建不存在的 topic
@Configuration
public class KafkaConfiguration {
@Bean
public NewTopic topicSingle() {
return new NewTopic("topic-single",3, (short) 1);
}
@Bean
public NewTopic topicBatch() {
return new NewTopic("topic-batch",3, (short) 1);
}
}@Configuration
public class KafkaConfiguration {
@Bean
public NewTopic topicSingle() {
return new NewTopic("topic-single",3, (short) 1);
}
@Bean
public NewTopic topicBatch() {
return new NewTopic("topic-batch",3, (short) 1);
}
}生产者
@RestController
@RequestMapping("/kafka")
public class KafkaProducerTest {
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
private final ListenableFutureCallback<SendResult<String, String>> futureCallback = new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
assert result != null;
ProducerRecord<String, String> record = result.getProducerRecord();
System.out.println(StrUtil.format("Send message-> topic: {}, partition: {}, key: {}, value: {}", record.topic(), record.partition(), record.key(), record.value()));
}
@Override
public void onFailure(Throwable e) {
System.out.println(StrUtil.format("kafka Send message failed: {}", e.getMessage()));
}
};
/**
* 推送单条
*/
@PostMapping("/send")
public R<Boolean> sendMessage(@RequestBody KafkaMessage record) {
kafkaTemplate.send(record.getTopic(), record.getPartition(), record.getKey(), record.getValue()).addCallback(futureCallback);
return R.ok(true);
}
/**
* 推送多条
*/
@PostMapping("/send/batch")
public R<Boolean> sendMessageBatch(@RequestBody List<KafkaMessage> records) {
records.forEach(record -> kafkaTemplate.send(record.getTopic(), record.getPartition(), record.getKey(), record.getValue()).addCallback(futureCallback));
return R.ok(true);
}
}@RestController
@RequestMapping("/kafka")
public class KafkaProducerTest {
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
private final ListenableFutureCallback<SendResult<String, String>> futureCallback = new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onSuccess(SendResult<String, String> result) {
assert result != null;
ProducerRecord<String, String> record = result.getProducerRecord();
System.out.println(StrUtil.format("Send message-> topic: {}, partition: {}, key: {}, value: {}", record.topic(), record.partition(), record.key(), record.value()));
}
@Override
public void onFailure(Throwable e) {
System.out.println(StrUtil.format("kafka Send message failed: {}", e.getMessage()));
}
};
/**
* 推送单条
*/
@PostMapping("/send")
public R<Boolean> sendMessage(@RequestBody KafkaMessage record) {
kafkaTemplate.send(record.getTopic(), record.getPartition(), record.getKey(), record.getValue()).addCallback(futureCallback);
return R.ok(true);
}
/**
* 推送多条
*/
@PostMapping("/send/batch")
public R<Boolean> sendMessageBatch(@RequestBody List<KafkaMessage> records) {
records.forEach(record -> kafkaTemplate.send(record.getTopic(), record.getPartition(), record.getKey(), record.getValue()).addCallback(futureCallback));
return R.ok(true);
}
}WARNING
如果发送消息时,partition 不存在,会报错。
消费者
/**
* kafka 单条消费
*/
@KafkaListener(groupId = "single-test",topics = {"topic-single"})
public void onSingleMessage(ConsumerRecord<String, Object> record) {
System.out.println(StrUtil.format(">>> kafka single message, topic: {}, partition: {}, key: {}, value: {}",
record.topic(), record.partition(), record.key(), record.value()));
}
/**
* kafka 批量消费
*/
@KafkaListener(groupId = "batch-test",topics = {"topic-batch"})
public void onBatchMessage(List<ConsumerRecord<String, Object>> records) {
System.out.println(">>> Kafka batch message, size: " + records.size());
for (ConsumerRecord<String, Object> record : records) {
System.out.println(StrUtil.format("topic: {}, partition: {}, key: {}, value: {}",
record.topic(), record.partition(), record.key(), record.value()));
}
}
/**
* ack 手动提交
*/
@KafkaListener(groupId = "ack-mode-test", topics = {"topic-ack"})
public void manualImmediate(List<ConsumerRecord<String, Object>> records, Acknowledgment ack) {
System.out.println(">>> Kafka batch message, size: " + records.size());
for (ConsumerRecord<String, Object> record : records) {
System.out.println(StrUtil.format("topic: {}, partition: {}, key: {}, value: {}",
record.topic(), record.partition(), record.key(), record.value()));
}
// 手动确认:确认单当前消息(及之前的消息)offset 均已被消费完成
ack.acknowledge();
}/**
* kafka 单条消费
*/
@KafkaListener(groupId = "single-test",topics = {"topic-single"})
public void onSingleMessage(ConsumerRecord<String, Object> record) {
System.out.println(StrUtil.format(">>> kafka single message, topic: {}, partition: {}, key: {}, value: {}",
record.topic(), record.partition(), record.key(), record.value()));
}
/**
* kafka 批量消费
*/
@KafkaListener(groupId = "batch-test",topics = {"topic-batch"})
public void onBatchMessage(List<ConsumerRecord<String, Object>> records) {
System.out.println(">>> Kafka batch message, size: " + records.size());
for (ConsumerRecord<String, Object> record : records) {
System.out.println(StrUtil.format("topic: {}, partition: {}, key: {}, value: {}",
record.topic(), record.partition(), record.key(), record.value()));
}
}
/**
* ack 手动提交
*/
@KafkaListener(groupId = "ack-mode-test", topics = {"topic-ack"})
public void manualImmediate(List<ConsumerRecord<String, Object>> records, Acknowledgment ack) {
System.out.println(">>> Kafka batch message, size: " + records.size());
for (ConsumerRecord<String, Object> record : records) {
System.out.println(StrUtil.format("topic: {}, partition: {}, key: {}, value: {}",
record.topic(), record.partition(), record.key(), record.value()));
}
// 手动确认:确认单当前消息(及之前的消息)offset 均已被消费完成
ack.acknowledge();
}